CSCI
1300 Notes 6 Problem Decomposition
Compositionality, Again
Remember that we discussed how you can build a cathedral out of bricks, how the body is made of cells, and so on, and how all kinds of things can be represented using collections of numbers, which in turn are represented by blocks of bits. We've also discussed the fact that all kinds of ways of processing bits can be built up by combining lots and lots of very simple, basic operations, such as FIDO's instructions. These are all examples of compositionality.
We've also talked about layering in discussing composition. For example, an image is made of dots, dots are made of numbers, and numbers are made of bits. In designing a brick cathedral, you wouldn't want to have to think of the whole cathedral all at once. Rather, you'd think about how to make the various parts of the cathedral out of bricks (for example, buttresses, interior columns, sections of walls, vaults, and so on), and then how to assemble these parts to make the whole thing. These parts form a layer between the bricks and whole cathedral. There could be other layers, too: in thinking about how to make a buttress out of bricks you might find that the buttress itself has a number of parts, and you figure out how to make each of these parts out of bricks, separately.
In the same way, when you write a program, you don't want to think about the whole thing at once. Rather, you want to identify parts from which the program can be formed, and then figure out how these parts can be made out of C statements (which in turn will be made out of machine instructions, by the compiler.)
These parts usually correspond to functions (sometimes parts are so simple you just need a single statement or two to do them, and you don't define a function.) Almost always, you'll have more than one layer of functions. For example, suppose you are writing a program to draw a collection of shapes, using data in a file. It will use a function to read in the data, and a function to draw the shapes. The function that reads in the data will use a function that reads in one shape. That function will use a function to read in a line. The function that draws the shapes will use a function that draws one shape, and that function will use a function that draws a line.
When you are new to programming, the prospect of defining all these functions will seem daunting. Why not just write the code as one big stretch of statements? Over time, two things will happen. First, you'll get used to defining functions, and it won't seem so difficult. More importantly, you'll find that it is much easier to write a lot of separate functions correctly than it is to write one big stretch of statements. That's because each function only has to handle one small, simple part of the overall problem, even if the whole problem is very complicated.
Breaking a problem into parts
OK, so how do you take a problem and divide it up? With a cathedral, you might be able to just look at it and see where the natural divisions are. How do you do this with a problem? It takes practice, but there are a few natural divisions you will learn to spot. Here they are:
Sequence: do one thing and then another. Many problems involve a sequence of steps, like read in the data and then process it. You can write a function for each step.
Conditional: do one thing OR another thing, depending on some test. For example, if I am moving a chess piece, I do different things depending on what piece it is. I would write different functions to move each kind of piece (and I might write another function to use in testing what piece I have, though that might be simple enough I that I wouldn't need a function, depending on how the pieces are represented.)
Repetition: to process a collection of things, use a function that processes one thing, over and over. For example, to read in a collection of shapes, use a function that reads in one shape, over and over.
Recursion: describe how to solve a big problem by using a solution to a simpler problem of the same kind, and knowing how to solve the simplest form of the problem. We probably won't do much with this in this class, but I'm including it for completeness. Some of you may use it in your game playing program. Here's an example. The mathematical function factorial(n) is the product of the numbers from 1 to n, and factorial(1) is 1. I can compute factorial of n as n*factorial(n-1), unless n is 1, in which case the answer is just 1. Because factorial(n-1) is a simpler problem than factorial(n), and because eventually, as the problems get simpler and simpler, I get the problem factorial(1), for which I know the answer, I can solve any problem like this, no matter how big n is.
Top-down and Bottom-up Design.
The above ways of dividing up a problem into smaller problems can also be used to put functions together to get bigger functions. You'll find yourself doing both things in writing programs. Sometimes you'll be thinking about a big problem and breaking it down into smaller parts, and writing functions for the parts. Other times you'll think of functions that solve parts of a problem, and you'll write bigger functions that put those together to solve bigger parts of the problem.
The first approach is called top-down design. The image is that the "top" of a problem solution is a description of the overall goal. Down at the "bottom" are all the little details of the solution. As you move from the "top" downwards you getting more and more specific. In top-down design you proceed in that way: you put off dealing with details until you have worked out the general idea of what you are going do.
The opposite approach is called bottom-up. In this approach you begin by working out the details of parts of the solution, and then put these parts together to make a complete solution.
Either way, the key point is that you will be thinking of how to build a complicated solution out of layers of parts, not as one big tangle of code. Most of the parts will be functions, and each part will be simple and easy to understand (and to write) because it is doing just a part of the whole job.
Drawing pictures of programs
Many people like to draw pictures when they think about programs, to help them see how the pieces go together. Here's an example:
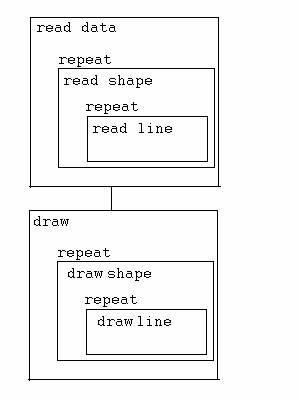
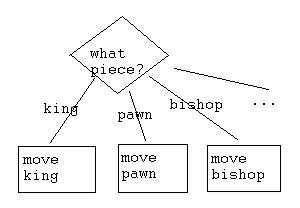
Here's how conditionals are often drawn, putting the test in a diamond:
Instead of drawing a picture, I sometimes make an outline, indenting as I subdivide each part. Here's the diagram above, in outline form.
program to read and draw shapes
read data
repeat: read
shape
repeat:
read line
draw
repeat: draw
shape
repeat:
draw line
Here's how I show tests in an outline:
test: what piece
case: king
move king
case: pawn
move king
case: bishop
move
bishop
Key point 1: Whether you draw a diagram or make an outline, it's crucial to make clear what is included in each of the parts. In the example above, the step "read data" is done only once, while the step "read shape" is repeated. Each time we do the step "read shape", the step "read line" is repeated.
Key point 2: If you are like most people, you will find that diagrams are easier to work with then you are new to problem decomposition. That's because the boxes make it easier to indicate what parts are included in what other parts. You have to be really careful with your indenting to make that clear in an outline. Eventually you may find that some form of outline fits better as part of the programming process: I usually begin a programming project by typing in an outline, which eventually gets converted to code as I work on it, or survives in the form of comments in the code. But feel free to use diagrams while you are learning.
Key point 3: There is almost always more than one decomposition that works for a give problem. In the "read and draw shapes" example we could do this:
program to read and draw shapes
repeat: read a
shape and draw it
read a shape
repeat:
read line
draw the
shape
repeat:
draw line
or even this:
program to read and draw shapes
repeat: read a
shape and draw it
repeat: read
a line and draw it
read line
draw line
Here are these outlines shown as diagrams:
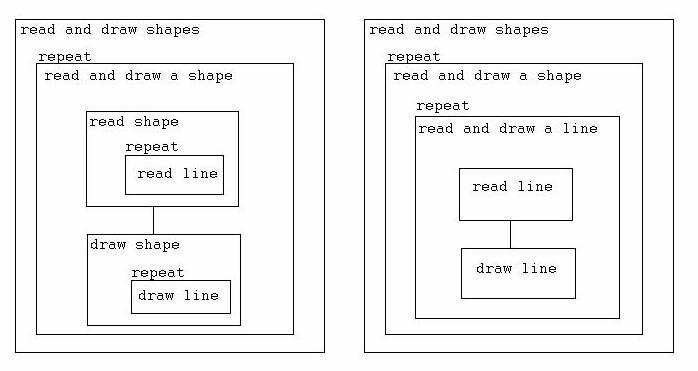
Notice the different process described by the three different designs. In the first design, we read all the shapes and store them somewhere. (The outline and diagram don't make it very clear that we have to store them, but if we don't, we won't be able to draw them later!) Then we go through and draw each of the stored shapes. In the second design, we read all the lines in one shape, and store them somewhere, and then we go through and draw the stored lines. Then we repeat this process for the second shape, and so on. In the third version, We read one line, draw it, and then go back and repeat that for all the lines. Here's a way to see that these are different, tracing the order in which read line steps and draw line steps are done.
First design:
read line, read line, read line,
read line,...., draw line, draw line, draw line, ...
Notice that all of the reads are done before any of the draws.
Second design:
read line, read line, read line,
draw line, draw line, draw line, read line, read line, read line, draw line,
draw line, draw line,...
Here the reads for the first shape are done, and then the draws for the first shape, then more reads, then more draws, and so on.
Third design:
read line, draw line, read line,
draw line, read line, draw line,...
Here each line is drawn as soon as it is read, so that reads and draws alternate.
Which is "correct"? All of them can work. The third design uses the least storage, but who cares about that (as long as we aren't talking about huge numbers of huge shapes.) On the other hand, its structure may not be as clear as that of designs 1 or 2, since the identity of shapes as a unit of information is more broken up. Your aim should be to develop a solution that is clear to you, and if version 1 is clearest, use it. Your designer's taste, your ability to find a really clear design for complicated problems, will develop with experience.... IF you make it a practice always to think about your design, not just to sit down and spew out code. Spewing out code just won't work for any but the simplest problems, however fluent you are with it.
Let's do an Example
A program that speaks Pig Latin. Pig Latin is an artificial children’s language that works by moving the first letter of a word to the end of the word, if the letter is a consonant, and adding the syllable “ay”, or just adding the syllable “way” to the end of a word if the first letter is not a consonant. For example, Pig Latin for “Clayton” is “laytoncay”; Pig Latin for “eggplant” is “eggplantway”. I’m going to use top-down design to write a program that translates words in a file into Pig Latin and prints them out.
Because diagrams are tedious to draw in these notes, I'll use outline form here.
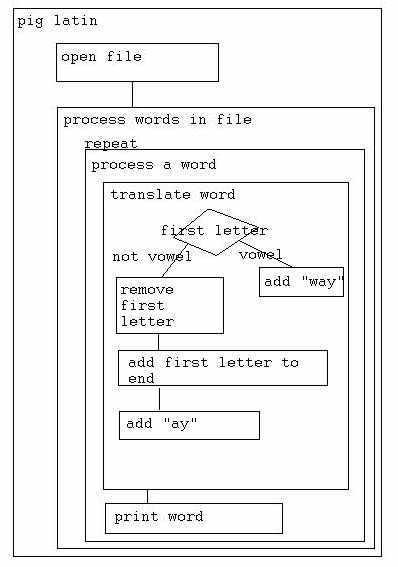
Here’s my outline
open the file
process the words in the file
repeat until no more words
process a word
translate the word
test the first letter
case: consonant
remove first letter
add letter to end
add “ay” to end
case: vowel
add “way” to end
print the word
If I think any of these pieces is too hard, or too complicated, I can subdivide them further.
Here's the design in diagram form:
From
outline to program
Now that I have an outline, I have to come up with functions for each of the parts. I do this in four stages: First I decide which of the parts of the outline really need functions (some are simple enough that I don't need a function, and some can be done using functions that already exist in some library, and I think of a good name for each of the functions I'll need to write. Second, for the functions I need to write, I work out how these functions will communicate with the rest of the program. That will determine whether they will return answers or not, and what arguments they will need. Third, I decide how I am going to represent the information the functions need, that is, what data types I will use. Fourth, I write the code for each function.
Here’s my outline, with names added for the functions I decide I'll need:
open the file //try_to_open()
process the words in the file //process_words()
repeat until no more words// I’ll use a while loop
process a word// process_word()
translate the word// translate_word()
test the first letter //no function; just an if
case: consonant
remove first letter //remove_first()
add letter to end //add_letter_to_end()
add “ay” to end//strcat()… it’s in the string library
case: vowel
add “way” to end// strcat()
print the word //just use printf()
Now, for each function, I work out what information the function needs to do its job, and what information it needs to produce. I distinguish these cases:
A function can get information it needs from the user, from a file, or from a program that calls it. Of these cases, the one I need to pay most attention to is the latter, because only that case affects how the function communicates with the rest of the program.
A function can put information on the screen, put it in a file, or give it to a program that calls it. Of these cases, the one I need to pay most attention to is the latter, because only that case affects how the function communicates with the rest of the program.
(There are a few other possibilities, like using getpixel() to get information from the screen, but we'll ignore these for now.)
Here's the list of functions in my example, with the needs/produces info added. When I just say needs or produces, with no qualification, I mean the needed information will come from a calling program, and information that is produced will be given to a calling program. When info will come from the user, or go to a file, for example, I say so.
try_to_open(): needs a file name, produces a valid file pointer
process_words(): needs a file pointer,
produces (Pig Latin) words on the screen
process_word(): needs a word, produces a
(Pig Latin) word on the screen
translate_word(): needs a word, produces a
(Pig Latin) word
remove_first(): needs a word, produces a
word
add_letter_to_end(): needs a word and a
letter, produces a word
Now I decide what data types I will use to represent the information that functions need and produce. Here's my list of data types for the example, working from the beginning:
a file name: array of char
a file pointer: pointer to FILE
a word: array of char
a letter: a single char
Now I declare a function for each piece of my outline. The needs and produces information guides me in determining what the function should return, and what arguments it needs, that is, determining the prototype for the function. Notice that information produced to the screen, or needed from the user, or from a file, will not show up as values returned or as arguments. Only information that must be gotten from a calling program, or sent to a calling program, will show up in the prototype.
The information a function needs to get from a calling program will come in as arguments. The information a function that must be sent to a calling program will either be returned OR put into the calling program's information holders using pointer arguments. I try to use return when I can, but I can only return one thing, and I can't return arrays, so sometimes I have to use arguments.
Here are my function declarations, running through the outline in order:
//try_to_open():
needs a file name, produces a valid file pointer
FILE
*try_to_open(char filename[]);
//process_words(): needs a file pointer, produces (Pig Latin) words on the
screen
void process_words(FILE* fp);
//process_word(): needs a word, produces a (Pig Latin) word on the screen
void process_word(char wd[]);
//translate_word(): needs a word, produces a (Pig Latin) word
void translate_word(char oldwd[],char newwd[]);
(I’d really like to have made this function return the new word, but
you can’t return arrays.)
//remove_first(): needs a word, produces a word
void remove_first(char original[], char shortened[]);
(I could have made this function shorten original, but in general it’s better
not to mess with your inputs in case the caller needs them for some other
purpose.)
//add_letter_to_end(): needs a word and a letter, produces a word
void add_letter_to_end(char original[],char letter, char
lengthened[]);
Note: None of these functions uses pointer parameters, on the surface. That’s because arrays are really handled as pointers. It also happens that none of my functions needs to produce more than one piece of information, which keeps things simple.
Now I write the code. If I've done a good job of breaking up the problem, nothing here will be difficult.
I worked through the list of function declarations above. As I worked, usually the function and argument names I used in the declarations told me enough about what the function was supposed to do for me to be able to write the functions. Sometimes I also looked back at the outline.
(Note: From here on, I'm going to give you a trace of what I really did in writing this program, mistakes and all. I believe that reading this will help you understand how you should think about your own code, and how to deal with the mistakes you will inevitably make, better than just looking at the finished product. Take some time to read it; you owe me a bunch of hours anyway, so use some for this.)
//try_to_open():
needs a file name, produces a valid file pointer
FILE *try_to_open(char filename[])
{
FILE* fp;
fp=fopen(filename,”r”);
if(fp)
return fp;
else exit(1);
}
//process_words(): needs a file pointer, produces (Pig Latin) words on the
screen
void process_words(FILE* fp)
{
char word[80];
while(fscanf(fp,”%s”,word)==1)
process_word(word);
}
//process_word(): needs a word, produces a (Pig Latin) word on the screen
void process_word(char wd[])
{
char newwd[80];
translate_word(wd,newwd);
printf(“%s”,newwd);
}
//translate_word(): needs a word, produces a (Pig Latin) word
void translate_word(char oldwd[],char newwd[])
{
if(oldwd[0]…
Golly! Here I find that I left something out of my outline! I need a
simple way to determine if this letter is a consonant or not. I don’t want to
write out a complicated test here. I’ll create a new function:
int is_vowel(char c)//easier to test for vowel than consonant
{
if((c==’a’)||(c==’e’)||(c==’i’)||(c==’o’)||(c==’u’))
return 1;
else return 0;
}
Now that I see how I’ve done this, I could have written this test right
into the if in translate_word(). But when you see the code I get for translate_word() now that I’ve written
the is_vowel() function, I think you’ll agree it’s
clearer:
void translate_word(char oldwd[],char newwd[])
{
if(!vowel(oldwd[0]))//if it’s not
a vowel
{
remove_first(oldwd,shortened); //I’ll have to //declare
this
add_letter_to_end(shortened,oldwd…
Golly! Here’s another tricky bit I want a function for: finding the
last letter (note: I’m making a mistake here…more later).
char last_letter(char wd[])
{
return wd[strlen(wd)-1];// if
there are 5 letters the last //is wd[4]
}
Again, I could have put this into the big function, but it’s nicer this
way:
void translate_word(char oldwd[],char newwd[])
{
if(!vowel(oldwd[0]))//if it’s not a
vowel
{
remove_first(oldwd,shortened); //I’ll have to //declare
this
add_letter_to_end(shortened,last_letter(oldwd),lengthened);
//have
to declare lengthened, too
strcat(lengthened,”ay”);//strcat() adds
to the //string you give it
strcpy(newwd,lengthened);
}
else
{
strcat(oldwd,”way”); //I don’t want to do this! It //changes oldwd, which may cause //trouble if somebody
calls this //fn
w/o realizing that
strcpy(newwd,oldwd);
}
}
Well, that’s a first draft for that function. I’m going to go back, add
the declarations, and find a way to avoid changing oldwd
there at the end.
void translate_word(char oldwd[],char newwd[])
{
char shortened[80,lengthened[80];
if(!vowel(oldwd[0]))//if it’s not
a vowel
{
remove_first(oldwd,shortened);
add_letter_to_end(shortened,last_letter(oldwd),lengthened);
strcat(lengthened,”ay”);//strcat() adds
to the //string you give it
strcpy(newwd,lengthened);
}
else
{
strcpy(newwd,oldwd);
strcat(newwd,”way”);
}
}
//remove_first(): needs a word, produces a word
void remove_first(char original[], char shortened[])
{
int i;
for(i=1;i<strlen(original);i++)
shortened[i-1]=original[i];
shortened[strlen(original)-1]=’\0’;
//end marker
}
This is the most complicated function yet… when writing this kind of
thing I draw a picture to show me where all the characters are so that I copy
the right things and put the end marker in the right place:
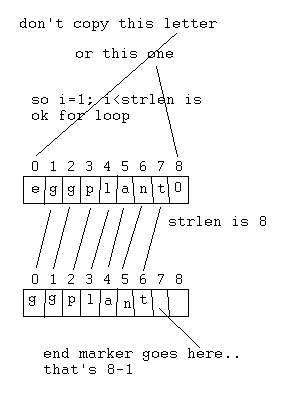
When you get more familiar with the string library, and with how arrays
work, you can do this:
void remove_first(char original[], char shortened[])
{
strcpy(shortened,&original[1]);
}
//add_letter_to_end(): needs a word and a letter, produces a word
void add_letter_to_end(char original[],char letter,char
lengthened[])
{
strcpy(lengthened,original);
lengthened[strlen(lengthened)]=letter;
lengthened[strlen(lengthened)+1]=’\0’;
//end mark
}
Process note: What I did in writing these function definitions, and what you should do, is to make a copy of the list of function declarations, and then work your way through it, writing the definitions as you go. Remember that each function declaration is just the header of the definition (the first line) with a semicolon added, so all you have to do is delete the semicolon, add the function body, and move on.
Putting the whole program together.
Remember the order: #includes, constant definitions, struct type declarations (if any), function declarations, function definitions.
You’ll see when you come to it that my main() function is really short, as it should be.
#include <stdio.h>
#include <string.h>
FILE *try_to_open(char
filename[]);
void process_words(FILE*
fp);
void process_word(char
wd[]);
void translate_word(char
oldwd[],char newwd[]);
void remove_first(char
original[], char shortened[]);
int
main()
{
process_words(try_to_open(“mypiglatininput.txt”));
return 0;
}
FILE *try_to_open(char filename[])
{
FILE* fp;
fp=fopen(filename,”r”);
if(fp)
return fp;
else exit(1);
}
void process_words(FILE*
fp)
{
char word[80];
while(fscanf(fp,”%s”,word)==1)
process_word(word);
}
void process_word(char
wd[])
{
char newwd[80];
translate_word(wd,newwd);
printf(“%s”,newwd);
}
void translate_word(char
oldwd[],char newwd[])
{
char
shortened[80,lengthened[80];
if(!vowel(oldwd[0]))//if it’s not a vowel
{
remove_first(oldwd,shortened);
add_letter_to_end(shortened,
last_letter(oldwd),lengthened);
strcat(lengthened,”ay”);//strcat() adds to //the string you give it
strcpy(newwd,lengthened);
}
else
{
strcpy(newwd,oldwd);
strcat(newwd,”way”);
}
}
int
is_vowel(char c)//easier to test for vowel than //consonant
{
if((c==’a’)||(c==’e’)||(c==’i’)||(c==’o’)||
(c==’u’))
return 1;
else return 0;
}
char last_letter(char
wd[])
{
return wd[strlen(wd)-1];// if there are 5 letters //the last is wd[4]
}
void remove_first(char
original[], char shortened[])
{
int
i;
for(i=1;i<strlen(original);i++)
shortened[i-1]=original[i];
shortened[strlen(original)-1]=’\0’; //end marker
}
void add_letter_to_end(char
original[],char letter, char lengthened[])
{
strcpy(lengthened,original);
lengthened[strlen(lengthened)]=letter;
lengthened[strlen(lengthened)+1]=’\0’; //end mark
}
Compiling and running the program.
When I compiled the program for the first time, I got several compiler errors, as follows. After each warning or error I’ve shown what the trouble was.
C:\cs1300\clayton>gcc -Wall n6.c
n6.c: In function `translate_word':
n6.c:35: `lengthened' undeclared (first use in this
function)
n6.c:35: (Each undeclared identifier is reported
only once
n6.c:35: for each function it appears in.)
n6.c:35: warning: left-hand operand of comma
expression has no effect
n6.c:35: parse error before `;
all above due to missing bracket in char
shortened[80,lengthened[80];
n6.c:36:
warning: implicit declaration of function `vowel'
I forgot to declare
this function that I added to my outline, and I forgot I named it is_vowel when I wrote the call.
n6.c:38:
`shortened' undeclared (first use in this function)
Also
caused by the missing bracket.
n6.c:39:
warning: implicit declaration of function `add_letter_to_end'
Somehow I forgot
this one when I collected the declarations.
n6.c:39:
warning: implicit declaration of function `last_letter'
This is another function
I added that I forgot to declare.
n6.c: At top level:
n6.c:55: warning: type mismatch with previous
implicit declaration
n6.c:39: warning: previous implicit declaration of `last_letter'
n6.c:55: warning: `last_letter'
was previously implicitly declared to return `in
t'
n6.c:66: warning: type mismatch with previous
implicit declaration
n6.c:39: warning: previous implicit declaration of `add_letter_to_end'
n6.c:66: warning: `add_letter_to_end'
was previously implicitly declared to retu
rn `int'
The remaining
warnings above come from having left out some of the function declarations.
When I tried the
corrected version, it compiled. I created this file for it to read:
here is some text
to be translated into
pig latin
But this is what I
got when I ran it:
C:\cs1300\clayton>a
ereeP■@☻└├ΘwP■@☻/─Θwayiswayomeeayexttayayoottayayayeettayayayayranslateddayayint
owayiggslateddayayayatinnateddayayayay
What could be
wrong? I can see some fragments of the right words in there, so it looks as if
it’s reading the file. One thing I notice is that the words are run together,
and I realize I need to print spaces between them. I figure doing that will
make it easier to see what else is wrong, so I replace
printf("%s",newwd);
by
printf("%s ",newwd);
and try again. This time I get
this:
C:\cs1300\clayton>a
ereeP■@☻└├ΘwP■@☻/─Θway isway omeeay exttayay
oottayayay eettayayayay ranslatedda
yay intoway iggslateddayayay atinnateddayayayay
Pretty
strange.
Some words, like “is” changed to “isway”, have
worked. But the first word is badly mangled, and the later words have odd
fragments left over in them. I’m going to see if I can find out what’s wrong
with the first word, “here”, first. First I read the code, looking for anything
obvious. I don’t see anything obvious, so I add code to print out some of the
intermediate results, like lengthened and shortened, that
show up along the way. My thinking is, don’t waste time reading over code if it
isn’t obvious what’s wrong: make the program tell you more about what it is
doing. Here is what I get (I’m just showing the processing for “here”:
C:\cs1300\clayton>a
in translate oldwd is <here>
shortened
is <ere>
lengthened
is <ereeP■@☻└├ΘwP■@☻/─Θw>
lengthened
is <ereeP■@☻└├ΘwP■@☻/─Θway>
newwd
is <ereeP■@☻└├ΘwP■@☻/─Θway>
I can see that
removing the h has worked, but when I try to add it back onto the end I am
getting garbage. This suggests I am not placing the end marker correctly. Also,
I don’t see the h. So I read the code for add_letter_to_end().Now that I know where to
look, I see two problems. One is (I’m so silly!) I added the last letter to the
end, when I should have added the first letter! I did all that work to write a
function to get the last letter, when all I needed to use was the first letter
of the original word. To fix this I replace the line
add_letter_to_end(shortened,last_letter(oldwd),lengthened);
by
add_letter_to_end(shortened,oldwd[0],lengthened);
and I can get rid of the last_letter() function. So the story is that you can do the
right thing incorrectly, or, as I did here, you can do the wrong thing
correctly. Either way is a mistake!
My other problem is
a bit more tricky. In this code
lengthened[strlen(lengthened)]=letter;
lengthened[strlen(lengthened)+1]='\0';
//end mark
once I copy letter over the
original end mark in lengthened, strlen() can no
longer find how long the string is, because the end marker is now gone (strlen will find the next zero, somewhere along in memory,
and take that to be the end marker, including lots of garbage in the string.
Just shows that you have to be careful when you mess with those end markers!
This should do the trick:
int len;
len=strlen(lengthened);//figure
out how long this is before surgery
lengthened[len]=letter;
lengthened[len+1]='\0';
//end mark
I make this change,
and when I try again I get
C:\cs1300\clayton>a
in translate oldwd is <here>
shortened
is <ere>
lengthened
is <ereh>
lengthened
is <erehay>
newwd
is <erehay>
which looks right. I comment out
the printouts I used in debugging (I don’t remove them; I will need them if
something else is wrong). Now it works fine.
One last thing. I did a bad thing in the example program.
Everywhere I wrote a declaration like
char newwd[80];
I should have used
a constant:
char newwd[WORDSIZE];
that I would set up at the beginning
of the program, by saying
#define
WORDSIZE 80
Then if I decide I
want to allow longer words I only to need to make the change in one place.
So, here is the
final, cleaned up and corrected program, with the debugging printouts commented
out:
#include <stdio.h>
#include <string.h>
#define WORDSIZE 80
FILE *try_to_open(char filename[]);
void process_words(FILE* fp);
void process_word(char wd[]);
void translate_word(char oldwd[],char newwd[]);
int is_vowel(char c);
void remove_first(char original[], char shortened[]);
void add_letter_to_end(char original[],char letter,char
lengthened[]);
int
main()
{
process_words(try_to_open("mypiglatininput.txt"));
return 0;
}
FILE *try_to_open(char
filename[])
{
FILE* fp;
fp=fopen(filename,"r");
if(fp)
return fp;
else exit(1);
}
void process_words(FILE* fp)
{
char word[WORDSIZE];
while(fscanf(fp,"%s",word)==1)
process_word(word);
}
void process_word(char wd[])
{
char newwd[WORDSIZE];
translate_word(wd,newwd);
printf("%s
",newwd);
}
void translate_word(char oldwd[],char newwd[])
{
char shortened[WORDSIZE],lengthened[WORDSIZE];
//printf("in
translate oldwd is <%s>\n",oldwd);
if(!is_vowel(oldwd[0]))//if
it’s not a vowel
{
remove_first(oldwd,shortened);
//printf("shortened
is <%s>\n",shortened);
add_letter_to_end(shortened,oldwd[0],lengthened);
//printf("lengthened
is <%s>\n",lengthened);
strcat(lengthened,"ay");//strcat()
adds to the //string you give it
//printf("lengthened
is <%s>\n",lengthened);
strcpy(newwd,lengthened);
//printf("newwd is <%s>\n",newwd);
}
else
{
strcpy(newwd,oldwd);
strcat(newwd,"way");
}
}
int is_vowel(char c)//easier to test for vowel than consonant
{
if((c=='a')||(c=='e')||(c=='i')||(c=='o')||(c=='u'))
return 1;
else return 0;
}
void remove_first(char original[], char shortened[])
{
int i;
for(i=1;i<strlen(original);i++)
shortened[i-1]=original[i];
shortened[strlen(original)-1]='\0';
//end marker
}
void add_letter_to_end(char original[],char letter,char
lengthened[])
{
int len;
strcpy(lengthened,original);
len=strlen(lengthened);
lengthened[len]=letter;
lengthened[len+1]='\0'; //end mark
}
Reflections.
Take a few minutes to read over the final code. You should notice the following:
All of the functions are short.
All of the functions work in a simple way
Very few comments are needed to understand what is happening
The order of the function definitions makes it easy to understand the program, in that for any function you first see the whole story, and then can look below for the details if you want to. If you don't care how we test for vowels, don’t read that function.
Consider the functions at different levels in the outline. (The highest level is the whole job, the next highest is the functions that level calls, and so on down to the lowest level functions, which don't call any other functions.) The lowest level functions do only one simple thing. The higher level functions do simple combinations of things.
For this reason, none of the functions need many arguments. That eases the burden of having so many functions.
You can understand what a function is doing and how it does it separately from any functions that are not its parts. Also, you can understand a function without knowing how its parts do what they do: it's enough to know what the parts do.
For example, you can understand translate_word()
void translate_word(char oldwd[],char newwd[])
{
char
shortened[WORDSIZE],lengthened[WORDSIZE];
if(!is_vowel(oldwd[0]))//if it’s not a vowel
{
remove_first(oldwd,shortened);
add_letter_to_end(shortened,oldwd[0],lengthened);
strcat(lengthened,"ay");//strcat() adds to the //string you give it
strcpy(newwd,lengthened);
}
else
{
strcpy(newwd,oldwd);
strcat(newwd,"way");
}
}
without knowing how to remove the first letter, or how to add a letter onto a word.
That's the power of this approach, once you master it. No matter how big and complicated a problem is, you can always break it down into manageable parts, each of which you can tackle successfully. It may take time, but you'll get it done, and it will work.
There's further practical value, even beyond being able to solve big problems. The way this program is organized, you could change many aspects of it with little or no need to modify other parts. For example, if you changed to a different way of placing words in the file, only the functions that read from the file would need to be changed. Or suppose I want to change 'y' from a consonant to a vowel... I'd only have to change one line in the program. Changes of this kind are part of what is called software maintenance, and for real software the costs of maintenance are always greater than the original cost of writing the program. So writing the program from the start in a way that simplifies maintenance is very important.
Finally, notice that much of the process you've just seen has nothing to do with C. Only when you get to deciding specifically how to represent the information in the program, and then declare and define your functions does C come in. So you can (and you will) use this approach in any language. When you get into object oriented design some other ideas will become important too, but the problem decomposition skills you learn here will still be basic.
In real life you are unlikely to use top-down design in its pure form. As you get more skillful you will find that you mix up your approaches, sometimes doing design from the top, and sometimes starting by doing some design for a particularly difficult part of a problem before looking at the overall structure. The key point is, whether you work top down or bottom up, you will be looking for ways to use compositionality: divide up complicated programs into simple parts.
Programming Style Guide
For the remaining programming assignments I'll be examining the following aspects of your code. Each point has a two or three letter code that I'll use to indicate to you that I've found a problem of that type. You can avoid possible REDOs of your code by checking these points yourself. Also, keep this list so you can understand the marks on your papers when I return them.
II Incorrect indenting. There are many ways people indent their C code, but there's only one way that I'll accept from here on. This way has some advantages in readability, but more than that (1) if you are all consistent it helps me read your code, and (2) in real life you'll have to get used to following specific guidelines in your code, so why not get some practice now. [If you are used to some other way of indenting, your real-life co-workers will not care; they will expect you to follow the same rules they use. It's the same deal here.]
The rules are:
(a) opening curly braces are always placed on a line by themselves immediately below the first character of the keyword that controls the code in the brace, such as for, if, while or else, or the header of a function.
(b) lines inside braces are indented one tab stop to the right of the brace
(c) closing curly braces always occur on lines by themselves immediately below the corresponding opening brace
(d) when an if, else, for, while or similar construct controls a single statement, without curly braces, put the statement on the next line and indent the statement one tab stop.
For example,
void foo(int x, int y)
{
int
i;
for (i=0;i<N;i++)
{
printf("%d",i);
printf("%d",i*i);
if (i>M)
printf("M
exceeded.");
}
}
BN Bad name. Choose names for your functions and variables that convey what they are used for. Variables that are just used for indexing or counting in a loop should have short names like i or n or t.
DC Define constant. If the same value occurs in more than one place in your code define a constant. Also, if 5,6, and 7 (say) occur in your program, with 5 arising from 6-1 and 7 from 6+1, define a constant for 6 (say C) and express the others as C-1 and C+1. This kind of thing is crucial in making it easy to change your code. The slogan is, code one assumption in one place.
GV Global variable. As you know, these are forbidden in this class.
NC Needs comment. If there's something tricky about your code explain it in a comment.
UC Unnecessary comment. If you choose your names wisely you'll need very few comments. Comments that explain the obvious are bad; leave them out.
CTC Code too complex. Find a simpler approach.
FTL Function too long. A function should have no more than a dozen lines, besides declarations.
APA Avoid pointer argument. You should use pointer arguments only when you need to.
BUI Bad user interface. Is output clearly labelled, so the user can tell what the program has done? If user input is requested, is there a reasonable prompt? Is the user asked to provide information that the program should be able to figure out for itself?
DNW Does not work. This part of your code won't do what it needs to.
WNC Will not compile. If you turn in a program that will not compile, please mark it as such...I'll use this to indicate that I don't believe what you have given me would compile, when you haven't told me.
PDR Poor data representation. An example would be using separate variables to hold information that could be more easily handled in an array, or missing a chance to simplify by using a struct.
MFD Misplaced function declaration or definition. As discussed in the notes on functions, function declarations should preceed main() and function definitions should follow main().
USC Unsafe code. If the user makes an error, or if data values were different, this part of the program could blow up or behave unpredictably.
NGE Not general enough. This marks a place where your program is unnecessarily limited in what it can handle. For example, your route map drawing program might assume a certain number of routes. A word to the wise: more general programs are often shorter and simpler, not longer and more complex, than ones which handle special cases.
CF Combine functions. You have defined two or more different functions to do very similar jobs. This mark says you should define one function and use parameters to tell it what specific thing to do.
Exercise
I really want you to read the above notes! So, here are three exercises to encourage that.
0. What was the second bug (not compile error) that I found in my Pig Latin example?
1. The "Reflections" section above lists a number of points that I hope the notes make. Choose any three of these points, and describe specifically how the example illustrates it. Or, if you feel the example does not illustrate it, explain. Your descriptions should be a few sentences each, and should include code snippets.
2. Find a program you've submitted for any earlier assignment. Mark it up with comments indicating any violations of the style rules above. Also, correct these problems. Submit both the marked-up version and the corrected version. If all of your submissions have been perfect with respect to these points, borrow an imperfect submission from a classmate.
3. Diagram or outline a program that prompts the user for a sentence, and prints out the sentence, having replaced all instances of "I" or "me" by "you", and all instances of "you" by "I", and putting a question mark on the end. So if the user types "You don't like me" the program should respond "I don't like you?" DO NOT actually write the code for this, but do carry the design far enough that you feel the functions you need should be fairly simple to write. If you use type your outline, submit it in your email; if you use a handwritten outline or diagram on paper submit the paper in class.
(Optional: Write the code for this. You'll want to use the function gets(s) that reads a whole line of typing into a string s. Assume the words in the sentence are separated by blanks.)
4. Write a program that plays the mathematical mind reading trick shown in example below.
Example session (program output is shown in this font; user input in this font; comments that are not part of the session are in parens in this font):
Think of a number and make a note
of it. (user
thinks of 7)
Add one; multiply by 4; divide by
3 and tell me the remainder.
2
Now
take your original number.
Triple
it. OK so far? (user
now has 21)
yes (continue no matter what user says. Optional: if user does not say "yes", type "let's try again" and start over from the beginning)
If
you have more than one digit, add them up.
If
you still have more than one digit, add them up. Continue until you have one
digit. OK so far? (user now has 3)
yes (handle as above)
Divide
your answer by 3; add 5. (user now has 6)
Convert
your answer to a letter: 1 is a, 2 is b, and so on. OK so far? (user now has 'f')
yes
Think
of a state that starts with that letter.(
Now
think of the Statue of Liberty. OK so far?
yes
Come
on, the Statue of Liberty isn't in
Do
you want to play again?
yes
Think of a number and make a note
of it. (user
thinks of 26)
Add one; multiply by 4; divide by
3 and tell me the remainder.
0
Now
take your original number.
Triple
it. OK so far? (user
now has 78)
yes
If
you have more than one digit, add them up.
If
you still have more than one digit, add them up. Continue until you have one
digit. OK so far? (user adds 7 and 8 and gets 15, adds 1 and 5 and now has 6)
yes
Divide
your answer by 3; add 5. (user now has 7)
Convert
your answer to a letter: 1 is a, 2 is b, and so on. OK so far? (user now has 'g')
yes
Think
of a state that starts with that letter.(
Now
think of the Statue of Liberty. OK so far?
yes
Come
on, the Statue of Liberty isn't in
Do
you want to play again?
no
Thanks
for playing!
Turn in a diagram or outline showing your design, as well as your final code. Be sure your final code obeys the style rules.
Hints:
If the number the user types is 0, the state they
will be thinking of later is
Designing the repetition structure for this program may not be trivial. Since you don't know how many times they will play, you'll want a while loop. Give yourself a flag called "wants_to_continue", or something, set it to 1 initially, and use while(wants_to_continue==1)...; In the body, you run the session, and then ask if they want to play again. Set wants_to_continue to 0 or one depending on their answer.
Extras: If you have time left in your time commitment, get started working on your extra project, if you plan to do one, or work on the optional parts of Ex 3 or 4, or find something else related to programming to work on.
Don't forget to submit your time report!